Bronto for Fastly: Real-time CDN logging that actually scales
Mike Neville-O'Neill

A company processing 10s of TBs of Fastly logs daily through traditional logging vendors faces an impossible choice: pay enterprise prices for comprehensive logging or fly blind with minimal retention.
That's why most teams default to a 7-day retention window. It's not that they don't need historical data – it's that the economics don't work.
That was the exact situation for Contentstack, a leading global platform for delivering digital experiences. They now keep a full year of logs, run unlimited queries, and report 50% cost savings versus their previous solution.
Here's how the landscape is changing for Fastly users who refuse to compromise.
The real cost of restricted logging
Processing 10TB of Fastly logs daily can cost ~$30,000/month for ingestion alone on traditional platforms. To reduce costs, teams resort to:
- Abbreviating "EdgeResponseStatus" to "ers" to save bytes
- Sampling 1 in 100 requests and hoping issues appear in that sample
- Keeping only 7 days of data when seasonal patterns span months
- Limiting the data they ingest because storage costs compound monthly
When ingestion and storage are expensive, comprehensive logging becomes a luxury instead of standard practice. But what if the economics actually worked?
What changes when you can keep everything
Bronto uses the same ingestion-based pricing model as competitors, but our architectural efficiency (90% compression, optimized storage, purpose-built for logs) means you pay 50-90% less to ingest the same data. This changes everything.
Consider tracking API performance across multiple enterprise customers:
SQL
When ingestion is affordable, teams can actually keep the 30 days of high-volume logs the investigation requires. No sampling, no abbreviations, no compromises. With Bronto's efficient architecture making ingestion costs manageable, teams run these analyses continuously, catching performance degradation before customers notice. The difference: proactive optimization instead of reactive firefighting.
Why this matters for real work
This level of retention isn't a luxury; it's what teams need for routine analysis that drives business decisions. When Contentstack's customers report bandwidth overages, they need to understand consumption patterns since the beginning of the year. When status code 429s start appearing, they need 12-month trending to identify patterns. When debugging performance issues, they need complete context, not sampled data with gaps.
30-Day performance archaeology
A customer report of intermittent slowdowns triggered a deep investigation into their traffic patterns.
Analyzing max and average response times for a specific customer's API key over 30 days revealed that certain endpoints were gradually slowing down. This pattern is invisible in 7-day windows but clear with month-long data.
The team could see week-over-week degradation that would have caused a critical outage within weeks. With only 7 days of retention, they never would have seen it coming. The fix was implemented before users noticed any impact.
Multi-month error forensics
When 404 errors started appearing randomly across the CDN, the team needed to understand if this was a new issue or a recurring pattern. Filtering 90 days of complete logs for these errors, then grouping by cache type, shield, and point of presence revealed what looked like random errors were actually a cache invalidation race condition.
The pattern only occurred under specific geographic and timing conditions – impossible to diagnose without months of complete, unsampled data. With traditional platforms' 7-day windows and aggressive sampling, this would have remained an unsolved mystery.
The Intelligence layer: from logs to insights
Long-term retention unlocks intelligence, but only if you can actually query it. That's where Bronto's analytics engine comes in.
Run powerful SQL queries across months of data and get results in seconds. Set up change detection that automatically flags when cache hit rates drop or error patterns shift. Build easily filterable dashboards that let you click into any spike, any anomaly, any outlier. Or skip the SQL entirely. Bronto's AI-Powered dashboard builder turns natural language into visualizations: "Show me API response times by customer and region for the last 90 days." When something breaks BrontoScope interrogates your logs with context, correlating events, surfacing root causes, and explaining failures that would take hours to piece together manually.
This is what becomes possible when AI and traditional log analytics are built into the platform from day one:
API customer journey mapping
Track the entire API consumer journey from trial to enterprise:
- Initial exploration: Which endpoints do new users test first?
- Growth patterns: How does usage scale over months?
- Optimization: Which customers would benefit from dedicated infrastructure?
- Churn prediction: What usage patterns precede account downgrades?
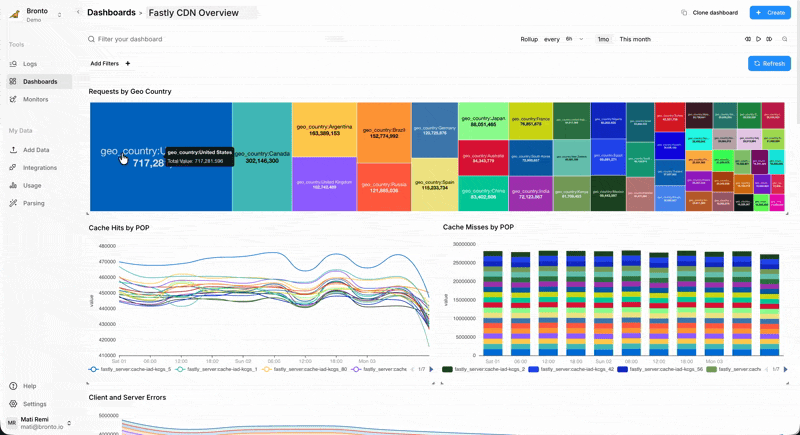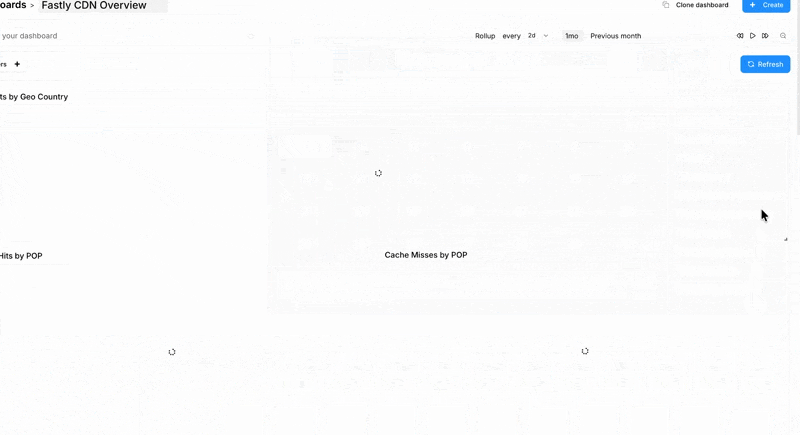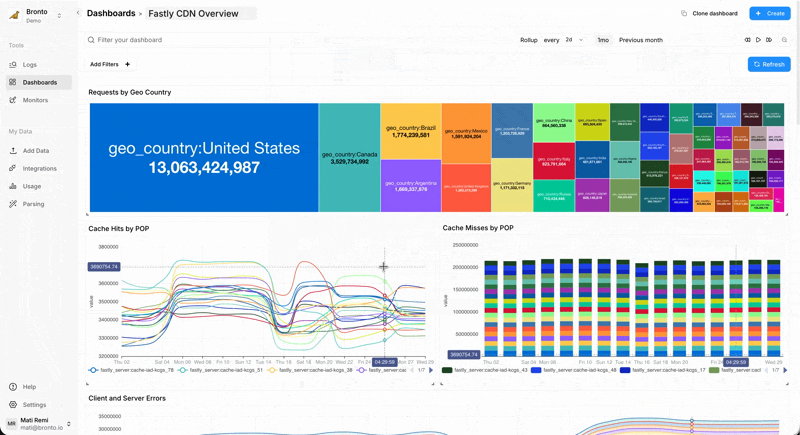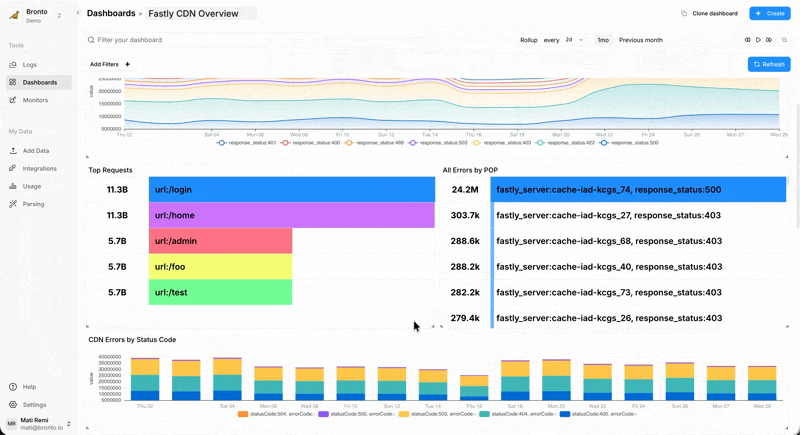
Intelligent cache optimization
With a year of data you can finally answer:
- How do cache hit ratios vary by season, not just by day?
- Which content genuinely needs global distribution vs. regional?
- When do cache warming strategies actually pay off?
- How do different shield configurations perform under various traffic patterns?
Security pattern recognition
Long-term retention enables more sophisticated threat detection:
- Bot networks that rotate through IP ranges over weeks
- Credential stuffing campaigns that evolve over months
- DDoS reconnaissance that occurs weeks before an attack
- Geographic attack patterns that shift with global events
Bronto for Fastly in summary:
Bronto Comparison — Log Coverage & Retention
| Before Bronto | After Bronto | |
|---|---|---|
| Field names abbreviated to save bytes | → | Full field names: Readable, searchable |
| Aggressive sampling: Keeping 1% of logs | → | 100% coverage: Every request, response, error |
| Short retention: 7 days max | → | 365-day retention: Full seasonal patterns |
| Blind spots: Log categories dropped | → | Complete visibility: CDN and compute logs |
Technical foundation: Built for Fastly's scale
Bronto's architecture was designed specifically for high-volume data streams like CDN logs, and integrates with Fastly through a built-in logging endpoint. Configure it once in your Fastly service settings and logs start streaming in minutes.
YAML
Why it scales:
- Elastic ingestion across multiple endpoints that grows with traffic
- Data compression reduces storage by 90%
- Time-series optimization for CDN access patterns
- Intelligent tiering keeps recent data hot, historical data accessible
- Column-oriented storage for efficient aggregations
(Check out these posts for more on Bronto's speed and scale)
The Platform Effect: When Every Team Has Access
When CDN logs become affordable and accessible, every team is empowered:
- Engineering debugs issues with complete historical context.
- Security investigates threats across meaningful timeframes.
- Product understands real usage patterns, not samples.
- Sales identifies expansion opportunities from actual usage.
- Finance accurately allocates costs to business units.
- Support resolves tickets with full forensic capability.
This isn't about saving money on logging (though 50%-90% savings helps). It's about removing the artificial constraints that prevent teams from fully understanding their infrastructure.
Bronto Express: from ingestion to insights in minutes with AI
This level of insight shouldn't require weeks of setup. To make this power immediately accessible, we created Bronto Express for Fastly. Using AI it takes raw log streams and dynamically builds Fastly specific queries, monitors and dashboards that are personalised for your organization.

Bronto Express: Fastly Preview
It includes:
- Pre-built dashboards: Real-time performance, geographic traffic, API usage, and security monitoring.
- Saved searches library: Templates for performance troubleshooting, security investigations, and business intelligence.
- Intelligent monitors: Automated alerts for performance degradation, traffic anomalies, and error rate thresholds.
It's the difference between raw logs and actionable intelligence.
With Bronto Express, the entire setup process is simplified:
- Create your Bronto instance (selecting the Fastly Express pack).
- Add Bronto as a logging endpoint in Fastly (5-minute configuration).
- Watch as pre-built dashboards populate with your data.
- Customize searches and alerts for your specific needs.
No agents. No forwarders. No complex pipelines. Just direct streaming from Fastly to instant insights.
The future of CDN intelligence
As edge computing becomes more complex, the gap between what teams need and what traditional logging vendors provide continues to widen. We're building for that future with specific features designed for Fastly CDN users:
-
Custom dashboards for Fastly metrics
-
Automated anomaly detection on CDN patterns
-
Cost optimization recommendations based on usage
-
Geographic visualization with interactive maps
-
AI-powered analysis for automatic pattern recognition
-
Predictive capacity planning based on historical trends
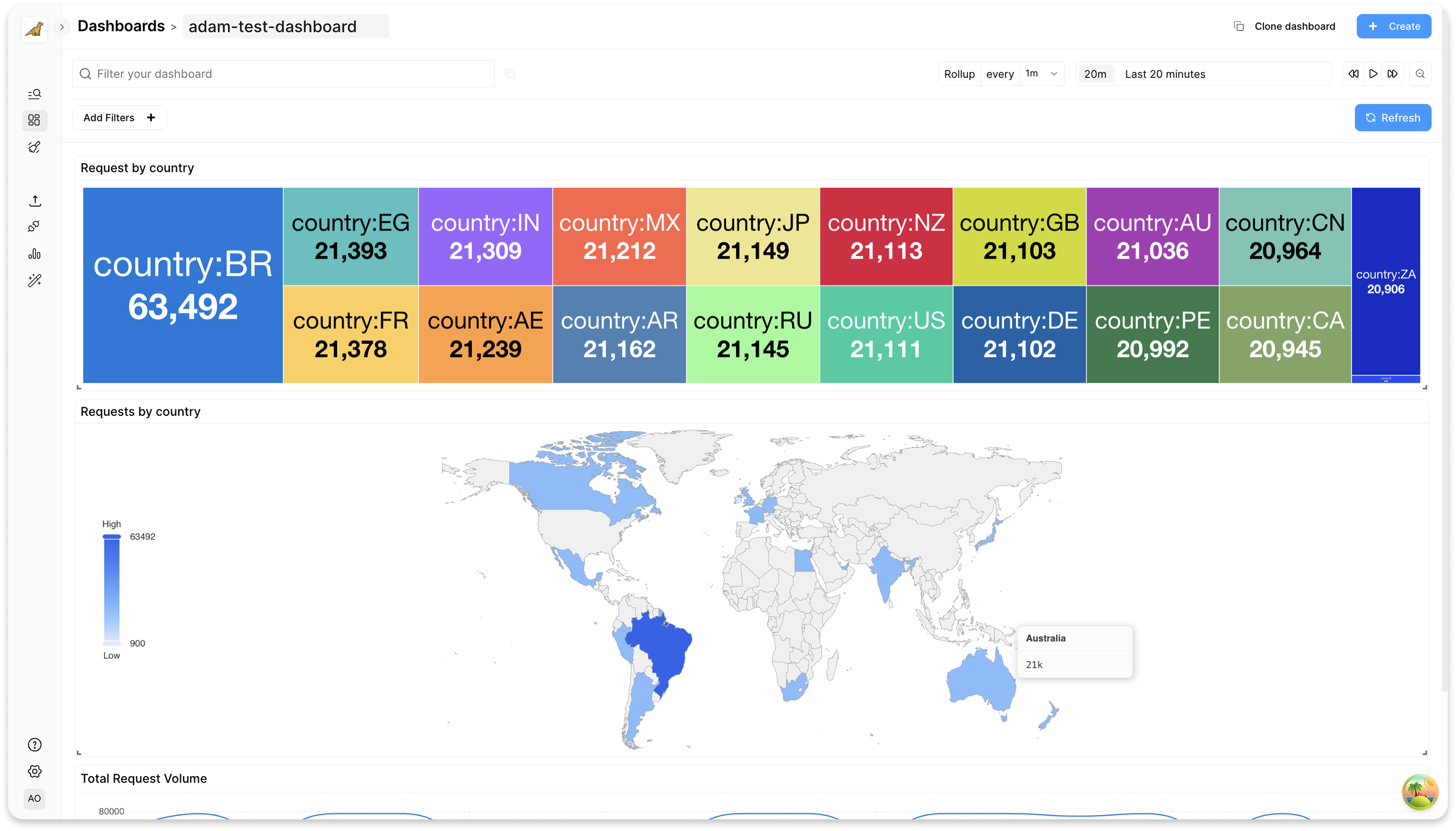
Join our movement
Forward-thinking companies like Contentstack have already eliminated the false economy of restricted CDN logging. They're keeping complete data, finding insights in long-term patterns, and making decisions based on comprehensive intelligence – all while paying 50% less.
Ready to hear what your logs have been trying to tell you?
Schedule a demo and we'll show you sub-second search across terabytes of your actual CDN data – with 12-month retention and no compromises.
Try Bronto free for 14 days
Centralize your agent and infrastructure telemetry in one platform with sub-second search and 12-month hot retention. No credit card required.