The 4L's of Logging - the New Standard for the AI era
Noel Ruane

Why Enterprise AI needs logging platforms with 4L's
Traditionally in the world of logging it was said there were 3Ls - low cost, low latency and large scale - and end users would have to compromise by choosing 2 of the 3.
Although it wasn’t a hard technical rule, until recently the logging products available in the marketplace suggested no one had cracked the 3Ls problem. Solutions typically fell into one of 3 categories:
- Expensive and fast. Think Datadog, ELK type solutions
- Slow and cheap(er). But actually still relatively expensive when you search - think index-free solutions like Grafana Loki
- Tweeners. Expensive and still relatively slow and not great at scale. Think Cloudwatch, Google Cloud Logging – what we often refer to as the subpar solutions.
Anyone who's ever hired builders to help with home improvement knows the iron rule: fast, cheap, or quality – pick two. You can't have all three.
But at the risk of stating the obvious, the world has changed utterly with the entry of AI into the mainstream and the recent advances in generative AI in particular. As everyone builds and innovates around LLMs and agents, and where agents can interrogate your data and solve problems at a completely different scale to before, it’s never been more essential to achieve the 3L's of logging. In fact with the arrival of AI there's an additional requirement that needs to be added to the list – Long term retention.
3 becomes 4: What long term retention opens up
Long term retention opens up your logs to a new set of use cases beyond operational emergency use cases. With a short retention window (3, 15, 30 days provided by today’s solutions) logs can be accessed for outages and system issues that are severe enough to warrant immediate attention.

But for lower level issues or for business or support related use cases long term retention is key. A common example is comparing customer metrics (e.g. customer API request latencies, or key customer conversion numbers) month on month, looking at how they are affected by seasonality or whether they improved or worsened over time. You might want to look at customers in aggregate to spot trends or at the specific customer level ahead of a customer QBR, for example.
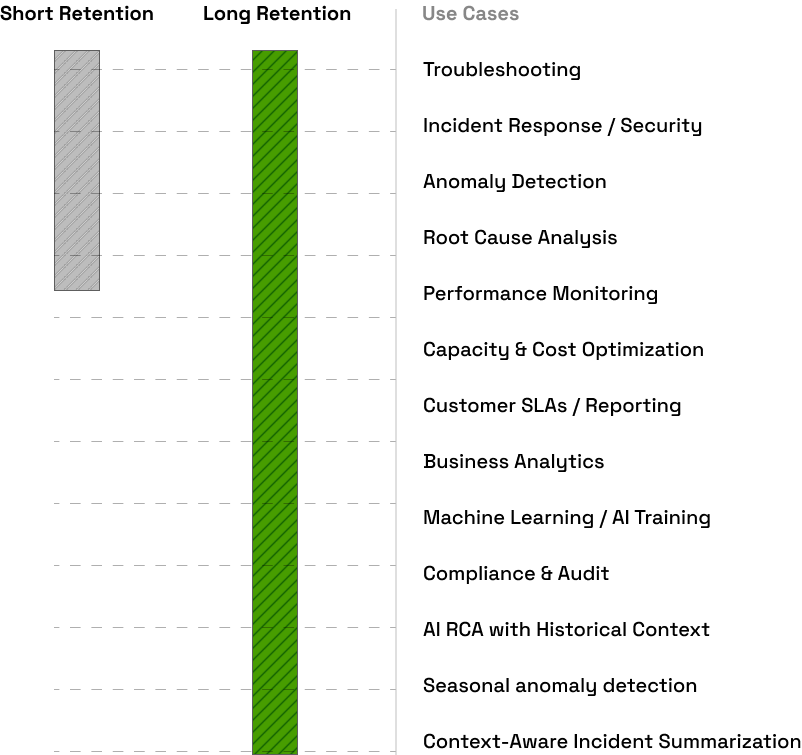
Support issues can be reported that have been recent, or ongoing over a course of months. Being able to look at the data beyond a few days can be key to providing an acceptable level of customer support and addressing customer issues fully and as they would expect.
In an AI world where you have agents that can interrogate your data and solve problems at a completely different scale, long term retention is a key requirement for any logging solution. By this we mean long term ‘hot’ data and not the cumbersome, time consuming and costly process of log rehydration from archives that most providers have built. The other way people solve this today is by throwing logs into S3 and then spinning up Athena to search them - again another great example of ‘Toil’ in the world of logs that needs to be addressed.
The importance of ‘long term hot data’ has been borne out by our own customers where we see the longer data retention folks have the more use cases that open up, searching is performed over longer time periods and the more value customers get from their data (see Tracey’s law). This value will only increase as agents become more powerful and prevalent.
The 4Ls of logging sets the new standard in the AI era
Microsoft’s Satya Nadella called this out recently when he talked about AI as being at the intersection of where intelligence meets data – If you don’t have the data you can't point AI at it. He mentioned specifically new requirements for data in an AI era as being:
- Data that is always and easily Accessible (Large Scale)
- Retained for the long term so that it can be utilised by AIs for analysis and taking action (Long-Term Retention)
- Cost Efficient in terms of storage and search - as volumes are going to see exponential growth (Low Cost)
- Fast in terms of search and querying the data (Low Latency)
“The volume of generated data, especially unstructured data, is projected to skyrocket to 612 zettabytes by 2030, driven by the wave of ML/AI excitement and synthetic data produced by generative models across all modalities. (One zettabyte = one trillion gigabytes or one billion terabytes.)" - Bessemer Venture Partners Roadmap for AI Infrastructure.
Log data is one specific data type that this applies to and its importance is only increasing as we all drive to adopt AI. Reasons for this include:
- Systems of action are replacing systems of record: As we move to a world where AI native apps don’t just store data, but actually act on it, retaining your log data and having it accessible and hot means that your AI models can actually do something with it. Gone are the days of retaining logs for 30 days and then locking them away in an object store, where you can 'break the glass' and rehydrate them in case of emergency. As AI evolves (and its evolving pretty quickly) data is going to be king and analysis will be cheap as AI takes over doing a lot of the heavy lifting from regular humans
- Logs for AI led Root Cause Analysis (RCA): Right now we are already seeing AIs performing RCA using log data to help teams solve problems faster. Our BrontoScope capability, for example, is already helping teams reduce MTTR significantly. BrontoScope reduces the time spent understanding the scope and impact of a specific error event by automatically running an investigation that assesses how widespread the error is. BrontoScope will figure out what queries to run, assess the results, run further queries and provide an immediate assessment of the severity and scope of the issue along with recommendations as to how to resolve it. It can save anywhere from minutes to hours and allows the end user to easily assess and verify the results. See the video demo below for BrontoScope in action and a deep dive on how the tech actually works here. We are going to showcase more advanced AI-led RCA going forward – particularly as MCP becomes standard, which will allow log data to be analysed with additional context and information from other systems. This is typically what an engineer does manually today as he/she pieces together the evidence to get to the root of an issue.
- LLMS are non-deterministic: Given the non-deterministic nature of LLMs, logs will play an even more important role when trying to understand what happened in these systems, whether from a support, debugging, audit, security or compliance perspective. Given that the same action can deliver different results, maintaining logs will be very important to show exactly what has happened in these systems. Want to start logging from your LLM to Bronto - check out our guide on collecting your Ollama logs.
- Regulation: Related to the last point, EU regulation, for example, will require logs of certain higher risk AI systems to be kept for at least 6 months from 2026.
Bronto is the only platform that achieves the 4L's of logging and is setting a new standard for the AI era
With Bronto you get the 4L’s:
- Low cost: we are a fraction of the cost of existing providers (cents per GB vs $$ per GB)
- Low latency: Subsecond search whether searching logs from 2 seconds ago or 2 years ago
- Large scale: All your logs are in one place, we have built Bronto for PB scale and beyond
- Long-term retention: Always hot (years of retention vs days)
In addition, Bronto is a full logging as a service platform, so you don’t need to manage anything.
A purpose built adaptive technology for log data that optimizes based on the shape of your data and queries
How is Bronto able to do this? The short answer is that we treat logs as a first class citizen when it comes to it being a unique data type and as such we have built a purpose built data store for logs.
Up until this point vendors have always repurposed existing datastores for logging - examples include:
- Elastic search: has been at the core of most logging solutions over the past two decades - super fast, as it just indexes pretty much everything, but super expensive due to data bloat and the fact that its so hard to manage
- Clickhouse: More recently vendors have turned to repurposing Clickhouse. It’s great for metrics, good for some logs, but only if you know the shape of them in advance which is a non runner for a logging platform. We have a full write up here on why Clickhouse fails as a general purpose logging solution
- Snowflake: Vendors like Observe have turned to Snowflake to try to address the cost problem around logging, however customers regularly complain about search latency and burning through CPU credits as they have to throw power at the problem when searching large data volumes (Proro-tip: get a Tegus subscription to hear direct on what customers saying)
The simple learning that we’ve gleaned from two decades in this space is that not all log data should be treated equally. Don’t just ‘index everything’ (as in the case of inverted indexes) or at the other extreme ‘index nothing’ as in the case of index free solutions.
Instead we take a more thoughtful approach and our system adapts and optimizes based on the shape of your data and the types of queries you run.
These optimizations are built into every layer of our system and are backed by decades of research and innovation carried out by our team of logging experts. At the core of any logging platform is how you index, store and search the data. As such, optimizations and the ability to adapt to the data and queries must happen at each of these layers.
Indexing: At the indexing layer we combine multiple, patent-pending, adaptive, compact indexes and optimizations. Indexing is adaptive – the platform automatically decides on which to use based on the data and queries it sees. Techniques include bloom filters, summary indexes, partition indexing, automatic log to metric conversion and a number of patent-pending technologies.
Storage: Our storage tier routes the data to the most appropriate storage structure based on the shape of the data and how it is going to be searched. Here we utilize techniques such as columnar store, specialised data structures, high compression, partial decoding, and storage tier coordination.
Search: Within the search layer we have specialised algorithms that are applied depending on the query being run - these are also highly parallelized so that they can be applied to data at any scale
For further reading check out Why Bronto is so fast at searching logs or for a more general overview of the problem - our Log management cost trap series, part 1- ingestion, part 2 - storage and part 3 - search do an amazing job of explaining some of the intricacies of solving this problem.
Modern cloud, muti-tentanted architecture with NO maintenance.
This part is often overlooked but extremely important. We see a number of vendors trying to solve the cost problem by deploying within an organisation's cloud (BYOC) and using the customer’s hardware to reduce the cost - making everything look cheaper. This requires deploying a logging platform into your cloud environment and having the vendor then manage this in your environment. We can maybe understand this in the case of tight data regulation – but otherwise it feels to us like overly complex for the customer and a backward step.
In contrast Bronto is built on a modern cloud multi-tenated architecture with no setup, maintenance or management required by the customer. We, of course, take advantage of separation of storage and compute, and our architecture espouses solid design principles such as independently scaling services for the ability to scale quickly.
AI = the intersection of intelligence & data
If your current provider is building AI capabilities on top of an old/repurposed/expensive logging platform (with 2 L’s instead of 4) you are not going to be able to take full advantage of the AI revolution.
We are excited to see what the next wave of capabilities bring as we continue to build log-specific capabilities that derive more value by utilising AI – sitting on top of a platform that is low cost, has low latency, runs at large scale and provides long term data retention that is always hot.
Do you want to learn more about the intersection of intelligence and log data. Request a demo of Bronto here!
Try Bronto free for 14 days
Centralize your agent and infrastructure telemetry in one platform with sub-second search and 12-month hot retention. No credit card required.